Clusters On Kubernetes¶
This document describes an architecture of Galera and RabbitMQ Clusters running in containers within Kubernetes pods and how to setup those in OpenStack on top of Kubernetes from deployment and networking standpoints. In addition to it, this document includes overview of alternative solutions for implementing database and message queue for OpenStack.
RabbitMQ Architecture with K8s¶
Clustering¶
The prerequisite for High Availability of queue server is the configured and working RabbitMQ cluster. All data/state required for the operation of a RabbitMQ cluster is replicated across all nodes. An exception to this are message queues, which by default reside on one node, though they are visible and reachable from all nodes. [1]
Cluster assembly requires installing and using a clustering plugin on all servers. The following choices are considered in this document:
rabbit-autocluster¶
Note that the plugin ‘rabbitmq-autocluster’ has unresolved issue that can cause split-brain condition to pass unnoticed by RabbitMQ cluster. This issue must be resolved before this plugin can be considered production ready.
The RabbitMQ cluster also needs proper fencing mechanism to exclude split brain conditions and preserve a quorum. Proposed solution for this problem is using ‘pause_minority’ partition mode with the rabbit-autocluster plugin, once the issue with silent split brain is resolved. See the following link for the proof of concept implementation of the K8s driven RabbitMQ cluster: https://review.openstack.org/#/c/345326/.
rabbit-clusterer¶
Plugin ‘rabbitmq-clusterer’ employs more opinionated and less generalized approach to the cluster assembly solution. It is also cannot be directly integrated with etcd and other K8s configuration management mechanisms because of static configuration. Additional engineering effort required to implement configuration middleware. Because of that it is considered a fallback solution.
Replication¶
Replication mechanism for RabbitMQ queues is known as ‘mirroring’. By default, queues within a RabbitMQ cluster are located on a single node (the node on which they were first declared). This is in contrast to exchanges and bindings, which can always be considered to be on all nodes. Queues can optionally be made mirrored across multiple nodes. Each mirrored queue consists of one master and one or more slaves, with the oldest slave being promoted to the new master if the old master disappears for any reason. [2]
Messages published to the queue are replicated to all members of the cluster. Consumers are connected to the master regardless of which node they connect to, with slave nodes dropping messages that have been acknowledged at the master. Queue mirroring therefore aims to enhance availability, but does not distribute load across nodes (all participating nodes each do all the work). It is important to note that using mirroring in RabbitMQ actually reduces the availability of queues by dropping performance by about 2 times in performance tests. See below for the list of issues identified in the RabbitMQ mirroring implementation. [6-13]
There are two main types of messages in OpenStack:
- Remote Procedure Call messages carry commands and/or requests between microservices within a single component of OpenStack platform (e.g. nova-conductor to nova-compute).
- Notification messages are issued by a microservice upon specific events and are consumed by other components (e.g. Nova notifications about creating VMs are consumed by Ceilometer).
In proposed OpenStack architecture, only notification queues are mirrored as they require durability and should survive a failure of any single node in the cluster. All other queues are not, and if the instance of RabbitMQ server that hosts a particular queue fails after a message sent to that queue, but before it is read, that message is gone forever. This is a trade-off for significant (2 times) performance boost in potential bottleneck service. Potential drawbacks of this mode of operation are:
- Long-running tasks might stuck in transition states due to loss of messages. For example, Heat stacks might never leave spawning state. Most of the time, such conditions could be fixed by the user via API.
Data Persistence¶
OpenStack does not impose requirements for durable queues or messages. Thus, no durability required for RabbitMQ queues, and there is no ‘disk’ nodes in cluster. Restarting a RabbitMQ node then will cause all data of that node to be lost, both for RPC and Notification messages.
- RPC messages are not supposed to be guaranteed, thus no persistence is needed for them.
- Notifications will be preserved by mirroring if single RabbitMQ node fails (see above).
Networking Considerations¶
RabbitMQ nodes address each other using domain names, either short or fully-qualified (FQDNs). Therefore hostnames of all cluster members must be resolvable from all cluster nodes, as well as machines on which command line tools such as rabbitmqctl might be used.
RabbitMQ clustering has several modes of dealing with network partitions, primarily consistency oriented. Clustering is meant to be used across LAN. It is not recommended to run clusters that span WAN. The Shovel or Federation plugins are better solutions for connecting brokers across a WAN. Note that Shovel and Federation are not equivalent to clustering. [1]
Kubernetes Integration¶
Clustering plugins need configuration data about other nodes in the cluster. This data might be passed via etcd to RabbitMQ startup scripts. ConfigMaps are used to pass the data into containers by Kubernetes orchestration.
The RabbitMQ server pods shall be configured as a DaemonSet with corresponding service. Physical nodes shall be labelled so as to run the containers with RabbitMQ on dedicated nodes, one pod per node (as per DaemonSet), or co-located with other control plane services.
PetSets are not required to facilitate the RabbitMQ cluster as the servers are stateless, as described above.
Proposed solution for running RabbitMQ cluster under Kubernetes is a DaemonSet with node labels to specify which nodes will run RabbitMQ servers. This will allow to move the cluster onto a set of dedicated nodes, if necessary, or run them on the same nodes as the other control plane components.
Alternatives¶
ZeroMQ¶
This library provides direct exchange of messages between microservices. Its architecture may include simple brokers or proxies that just relay messages to endpoints, thus reducing the number of network connections.
ZeroMQ library support was present in OpenStack since early releases. However, the implementation assumed direct connections between services and thus a full mesh network between all nodes. This architecture doesn’t scale well. More recent implementations introduce simple proxy services on every host that aggregate messages and relay them to a central proxy, which does host-based routing.
Benchmarks show that both direct and proxy-based ZeroMQ implementations are more efficient than RabbitMQ in terms of throughput and latency. However, in the direct implementation, quick exhaustion of network connections limit occurs at scale.
The major down side of the ZeroMQ-based solution is that the queues don’t have any persistence. This is acceptable for RPC messaging, but Notifications require durable queues. Thus, if RPC is using ZeroMQ, the Telemetry will require a separate messaging transport (RabbitMQ or Kafka).
Galera Architecture with K8s¶
Galera is synchronous multi-master database cluster, based on synchronous replication. At a high level, Galera Cluster consists on database server that uses Galera Replication plugin to manage replication. Through the wsrep API, Galera Cluster provides certification-based replication. A transaction for replication, the write-set, not only contains the database rows to replicate, but also includes information on all the locks that were held by the database during the transaction. Each node then certifies the replicated write-set against other write-sets in the applier queue. The write-set is then applied, if there are no conflicting locks. At this point, the transaction is considered committed, after which each node continues to apply it to the tablespace. This approach is also called virtually synchronous replication, given that while it is logically synchronous, the actual writing and committing to the tablespace happens independently, and thus asynchronously on each node.
How Galera Cluster works¶
The primary focus is data consistency. The transactions are either applied to every node or not all. In a typical instance of a Galera Cluster, applications can write to any node in the cluster and transaction commits, (RBR events), are then applied to all the servers, through certification-based replication. Certification-based replication is an alternative approach to synchronous database replication, using group communication and transaction ordering techniques. In case of transaction collisions the application should be able to handle ‘failed’ transactions. Openstack Applications use oslo.db which has retry logic to rerun failed transaction.
Starting the cluster¶
By default, nodes do not start as part of the Primary Component (PC). Instead, they assume that the Primary Component exists already somewhere in the cluster.
When nodes start, they attempt to establish network connectivity with the other nodes in the cluster. For each node they find, they check whether or not it is a part of the Primary Component. When they find the Primary Component, they request a state transfer to bring the local database into sync with the cluster. If they cannot find the Primary Component, they remain in a nonoperational state.
There is no Primary Component when the cluster starts. In order to initialize it, you need to explicitly tell one node to do so with the –wsrep-new-cluster argument. By convention, the node you use to initialize the Primary Component is called the first node, given that it is the first that becomes operational.
When cluster is empty, any node can serve as the first node, since all databases are empty. In case of failure (power failure) the node with the most recent data should initialize Primary Component.
Node Provisioning¶
There are two methods available in Galera Cluster to provision nodes:
- State Snapshot Transfer (SST) where a snapshot of entire node state is transferred
- Incremental State Transfer (IST) where only missing data transactions are replayed
In SST, the cluster provisions nodes by transferring a full data copy from one node to another. When a new node joins or when it was offline (or left behind cluster) longer than IST buffer a new node (JOINER) initiates a SST to synchronize data.
In IST, the cluster provisions a node by identifying the missing transactions on the JOINER to send them only, instead of transferring entire state.
Networking Considerations¶
Load Balancing is a key element of networking configuration of the Galera cluster. Load balancer must be coordinated with the cluster, in terms that it redirect write requests to appropriate Galera Pod which has Sync state. Communication with Galera Pods that have any other state (OPEN, PRIMARY, JOINER, JOINED, DONOR) should be prohibited. Load Balancer also ensures failover to hot stand-by instances and fencing of failed active nodes.
The following options are considered for load balancer in K8s integration of Galera:
Storage Considerations¶
Since every nodes in Galera Cluster has a copy of the data set at any time, there is no need to use networked storage (NFS, Ceph, GlasterFS). All Galera Pods can work with the local disk storage (Directory, LVM). From the Kubernetes standpoint, it means that local persistent volume must be mounted to Galera Pod on the same node. From the Kubernetes Scheduler standpoint, it means that Galera Pods should run on the nodes where Persistent Volume is created. At the same time, networking storage might be useful as in that case PV claimed on it can be assigned to any node eliminating bottleneck in Architecture. Using networking storage such as ceph might significantly improve SST operation though database write operations will be slower than local storage.
The following clustering solutions considered for Galera Cluster:
- Replication Controller with proxy (ProxySQL is used): An etcd cluster with startup scripts controlling assembly and liveliness of the cluster’s nodes, for example:
- PetSet:
- Replication controller with proxy and additional watcher
Replication Controller Schema with additional proxy and watcher¶
The proposed solution is based on the native Kubernetes state management with etcd providing distributed monitoring and data exchange for the cluster. Cluster operations will be triggered by Kubernetes events and handled by custom scripts.
Failover and fencing of failed instances of Galera Cluster is provided by scripts triggered by Kubernetes upon the changes in state and availability of the members of Galera Cluster. State and configuration information is provided by etcd cluster.
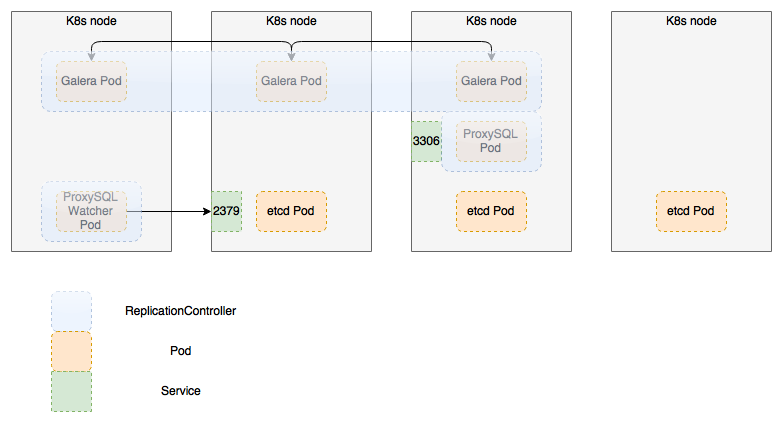
- Proposed architecture allows to quickly replace failing instances of MySQL server without need to run full replication. It is still necessary to restore the pool of hot-stand-by instances whenever the failover event occurs.
- Additional proxy is stateless, e.g. it does not contain state and can be re-scheduled by k8s in case of failure
- Watcher is stateless as well, and is capable of populating the state from etcd to ProxySQL
- Additional proxy brings the benefit of more granular control over
MySQL connections, which is not possible with k8s service:
- Forward all writes to one node or special group of nodes (not implemented in current scheme, but can be easily added), and Reads to the rest of the group;
- Central mysql cache;
- Rate limits on per-user basis;
- Hot-standby nodes can be added to the pool but not activated by default
- Storage considerations are the same as for PetSets, see below.
Future enhancements of this PoC may include:
- Rework custom bootstrap script and switch to election plugin for K8s.
- Integrate extended Galera checker that supports hostgroups (like this one)
Demo Recording¶
The following recording demonstrates how Galera cluster works as a Replication Controller on K8s 1.3 with ProxySQL middleware. It includes destructive test when one of instances of MySQL server in the cluster is shut off.
Open Questions¶
- ProxySQL requires management, and that is why watcher was written. Since it terminates queries, users/password should be managed in two places now: in MySQL and in ProxySQL itself.
- K8s does not have bare-metal storage provider (only cloud based ones), and it is crucial for any stateful application in self-hosted clouds. Until that is ready, no stateful application can actually go production.
PetSet Schema¶
Storage for database files shall be supported as one of the following options:
- a local file/LV configured as al HostPath volume and mounted to every pod in set;
- a remote SAN/NAS volume mounted to every pod;
- a volume or file on a shared storage (Ceph) configured as volume and mounted to every pod.
Persistent volumes for Galera PetSets must be created by the K8s installer, which is out of scope of this document.
Demo Recording¶
The following video recording <https://asciinema.org/a/87411> demonstrates how Galera MySQL cluster is installed and works as PetSet on Kubernetes with local volumes for persistent storage.
Galera Cluster Rebuild Problem¶
In case of general cluster failure or planned maintenance shutdown, all pods in Galera cluster are destroyed. When the new set of pods is started, they have to recover the cluster status, rebuild the cluster and continue from the last recorded point in time.
With local storage, Galera pods mount volumes created as a directory (default) or LVM volume (WIP). These volumes are used to store database files and replication logs. If cluster has to be rebuilt, all pods are assumed to be deleted, however, the volumes should stay and must be reused in the rebuild process. With local non-mobile volumes it means that new pods must be provisioned to the very same nodes they were running on originally.
Another problem is that during the rebuild process it is important to verify integrity and consistency of data on all static volumes before assembling the cluster and select a Primary Component. There are following criteria for this selection:
- The data must be readable, consistent and not corrupted.
- The most recent data set should be selected so the data loss is minimal and it could be used to incrementally update other nodes in the cluster via IST.
Currently, k8s scheduler does not allow for precise node-level placement of pods. It is also impossible to specify affinity of a pod to specific persistent local volume. Finally, k8s does not support LVM volumes out of the box.
References¶
This section contains references to external documents used in preparation of this document.
- RabbitMQ Clustering
- RabbitMQ High Availability
- https://github.com/percona/percona-docker/tree/master/pxc-56
- https://github.com/Percona-Lab/percona-xtradb-cluster-docker
- http://docs.openstack.org/developer/performance-docs/test_results/mq/rabbitmq/index.html
- https://github.com/rabbitmq/rabbitmq-server/issues/802
- https://github.com/rabbitmq/rabbitmq-server/issues/803
- https://github.com/rabbitmq/rabbitmq-server/pull/748
- https://github.com/rabbitmq/rabbitmq-server/issues/616
- https://github.com/rabbitmq/rabbitmq-server/pull/535
- https://github.com/rabbitmq/rabbitmq-server/issues/368
- https://github.com/rabbitmq/rabbitmq-server/pull/466
- https://github.com/rabbitmq/rabbitmq-server/pull/431