Kubernetes Master Tier For 1000 Nodes Scale¶
Table of Contents
- Kubernetes Master Tier For 1000 Nodes Scale
Introduction¶
This document describes architecture, configuration and installation workflow of Kubernetes cluster for OpenStack Containerised Control Plane (CCP) on a set of hosts, either baremetal or virtual. Proposed architecture should scale up to 1000 nodes.
Scope of the document¶
This document does not cover preparation of host nodes and installation of a CI/CD system. This document covers only Kubernetes and related services on a preinstalled operating system with configured partitioning and networking.
Monitoring related tooling will be installed on ready to use Kubernetes as Pods, after Kubernetes installer finishes installation. This document does not cover architecture and implementation details of monitoring and profiling tools.
Lifecycle Management section describes only Kubernetes and related services. It does not cover applications that run in Kubernetes cluster.
Solution Prerequisites¶
Hardware¶
The proposed design was verified on a hardware lab that included 181 physical hosts of the following configuration:
- Server model: HP ProLiant DL380 Gen9
- CPU: 2 x Intel(R) Xeon(R) CPU E5-2680 v3 @ 2.50GHz
- RAM: 264G
- Storage: 3.0T on RAID on HP Smart Array P840 Controller
- HDD: 12 x HP EH0600JDYTL
- Network: 2 x Intel Corporation Ethernet 10G 2P X710
3 out of the 181 hosts were used to install Kubernetes Master control plane services. On every other host, 5 virtual machines were started to ensure contention of resources and serve as Minion nodes in Kubernetes cluster.
Minimal requirements for the control plane services at scale of 1000 nodes are relatively modest. Tests demonstrate that three physical nodes in the configuration specified above are sufficient to run all control plane services for cluster of this size, even though an application running on top of the cluster is rather complex (i.e. OpenStack control plane + compute cluster).
Provisioning¶
Hosts for Kubernetes cluster must be prepared by a provsioning system of some sort. It is assumed that users might have their own provisioning system to handle prerequisites for this.
Provisioning system provides installed and configured operating system, networking, partitioning. It should operate on its own subset of cluster metadata. Some elements of that metadata will be used by installer tools for Kubernetes Master and OpenStack Control tiers.
The following prerequisites are required from Provisioning system.
Operating System¶
- Ubuntu 16.04 is default choice of operating system.
- It has to be installed and configured by provisioning system.
Networking¶
Before the deployment starts networking has to be configured and verified by underlay tooling:
- Bonding.
- Bridges (possibly).
- Multi-tiered networking.
- IP addresses assignment.
- SSH access from CI/CD nodes to cluster nodes (is required for Kubernetes installer).
Such things as DPDK and Contrail can be most likely configured in containers boot in privileged mode, no underlay involvement is required:
- Load DKMS modules
- Change runtime kernel parameters
Partitioning¶
Nodes should be efficiently pre-partitioned (e.g. separation of /,
/var/log, /var/lib directories).
Additionally it’s required to have LVM Volume Groups, which further will be used by:
- LVM backend for ephemeral storage for Nova.
- LVM backend for Kubernetes, it may be required to create several Volume Groups for Kubernetes, e.g. some of the services require SSD (InfluxDB), other will work fine on HDD.
Some customers also require Multipath disks to be configured.
Additional Ansible packages (optional)¶
Currently Kubespray project is employed for installing Kubernetes. It provides Calico and Ubuntu/Debian support.
Kubespray Ansible playbooks (or Kargo) are accepted into Kubernenes incubator by the community.
Ansible requires:
python2.7python-netaddr
Ansible 2.1.0 or greater is required for Kargo deployment.
Ansible installs and manages Kubernetes related services (see Components section) which should be delivered and installed as containers. Kubernetes has to be installed in HA mode, so that failure of a single master node does not cause control plane down-time.
The long term strategy should be to reduce amount of Ansible playbooks we have to support and to do initial deployment and Lifecycle Management with Kubernetes itself and related tools.
Node Decommissioning¶
Many Lifecycle Management scenarios require nodes decommissioning procedure. Strategy on decommissioning may depend on the customer and tightly coupled with Underlay tooling.
In order to properly remove the node from the cluster, a sequence of actions has to be performed by overlay tooling, to gracefully remove services from cluster and migrate workload (depends on the role).
Possible scenarios of node decommissioning for underlay tooling:
- Shut the node down.
- Move node to bootstrap stage.
- As a common practise we should not erase disks of the node, customers occasionally delete their production nodes, there should be a way to recover them (if they were not recycled).
CI/CD¶
Runs a chain of jobs in predefined order, like deployment and verification. CI/CD has to provide a way to trigger a chain of jobs (git push trigger -> deploy -> verify), also there should be a way to share data between different jobs for example if IP allocation happens on job execution allocated IP addresses should be available for overlay installer job to consume.
Non comprehensive list of functionality:
- Jobs definitions.
- Declarative definition of jobs pipelines.
- Data sharing between jobs.
- Artifacts (images, configurations, packages etc).
User experience¶
- User should be able to define a mapping of node and high level roles (master, minion) also there should be a way to define mapping more granularly (e.g. etcd master on separate nodes).
- After the change in pushed CI/CD job for rollout is triggered, Ansible starts Kubernetes deployment from CI/CD via SSH (the access from CI/CD to Kubernetes cluster using SSH has to be provided).
Updates¶
When new package is published (for example libssl) it should trigger a chain of jobs:
- Build new container image (Etcd, Calico, Hyperkube, Docker etc)
- Rebuild all images which depend on base
- Run image specific tests
- Deploy current production version on staging
- Run verification
- Deploy update on staging
- Run verification
- Send for promotion to production
Solution Overview¶
Current implementation considers two high-level groups of services - Master and Minion. Master nodes should run control-plane related services. Minion nodes should run user’s workload. In the future, additional Network node might be added.
There are few additional requirements which should be addressed:
- Components placement should be flexible enough to install most of the services on different nodes, for example it may be required to install etcd cluster members to dedicated nodes.
- It should be possible to have a single-node installation, when all required services to run Kubernetes cluster can be placed on a single node. Using scale up mechanism it should be possible to make the cluster HA. It would reduce amount of resources required for development and testing of simple integration scenarios.
Common Components¶
- Calico is an SDN controller that provides pure L3 networking to
Kubernetes cluster. It includes the following most important
components that run on every node in the cluster.
- Felix is an agent component of Calico, responsible for configuring and managing routing tables, network interfaces and filters on pariticipating hosts.
- Bird is a lightweight BGP daemon that allows for exchange of addressing information between nodes of Calico network.
- Kubernetes
- kube-dns provides discovery capabilities for Kubernetes Services.
- kubelet is an agent service of Kubernetes. It is responsible for creating and managing Docker containers at the nodes of Kubernetes cluster.
Plugins for Kubernetes should be delivered within Kubernetes containers. The following plugins are required:
- CNI plugin for integration with Calico SDN.
- Volume plugins (e.g. Ceph, Cinder) for persistent storage.
Another option which may be considered in the future, is to deliver plugins in separate containers, but it would complicate rollout of containers, since requires to rollout containers in specific order to mount plugins directory.
Master Components¶
Master Components of Kubernetes control plane run on Master nodes. The proposed architecture includes 3 Master nodes with similar set of components running on every node.
In addition to Common, the following components run on Master nodes:
- etcd
- Kubernetes
- Kubedns
- Kube-proxy (iptables mode)
- Kube-apiserver
- Kube-scheduler
- Kube-controller-manager
Each component runs on container. Some of them are running in static
pods in Kubernetes. Others are running as docker containers under
management of operating system (i.e. as systemd service). See
details in Installation section below.
Minion Components¶
Everything from Common plus:
- etcd-proxy is a mode of operation of etcd which doesn’t provide storage, but rather redirects requests to alive nodes in etcd clutser.
Optional Components¶
- Contrail SDN is an alternative to Calico in cases when L2 features required.
- Flannel is another alternative implementation of CNI plugin for Kubernetes. As Calico, it creates an L3 overlay network.
- Tools for debugging (see Troubleshooting below).
Component Versions¶
| Component | Version |
|---|---|
| Kubernetes | 1.4 |
| Etcd | 3.0.12 |
| Calico | 0.21-dev |
| Docker | 1.12.3 |
Components Overview¶
Kubernetes¶
kube-apiserver¶
This server exposes Kubernetes API to internal and external clients.
The proposed architecture includes 3 API server pods running on 3 different
nodes for redundancy and load distribution purposes. API servers run as
static pods, defined by a kubelet manifest
(/etc/kubernetes/manifests/kube-apiserver.manifest). This manifest is
created and managed by the Kubernetes installer.
kube-scheduler¶
Scheduler service of Kubernetes cluster monitors API server for unallocated pods and automatically assigns every such pod to a node based on filters or ‘predicates’ and weights or ‘priority functions’.
Scheduler runs as a single-container pod. Similarly to API server,
it is a static pod, defined and managed by Kubernetes installer.
Its manifest lives in /etc/kubernetes/manifests/kube-scheduler.manifest.
The proposed architecture suggests that 3 instances of scheduler run on 3 Master nodes. These instances are joined in a cluster whith elected leader that is active, and two warm stan-dy spares. When leader is lost for some reason, a re-election occurs and one of the spares becomes active leader.
The following parameters control election of leader and are set for scheduler:
- Leader election parameter for scheduler must be “true”.
- Leader elect lease duration
- Leader elect renew deadline
- Leader elect retry period
kube-controller-manager¶
Controller manager executes a main loops of all entities (controllers)
supported by Kubernetes API. It is similar to scheduler and API server
in terms of configuration: it is a static pod defined and managed by
Kubernetes installer via manifest file
/etc/kubernetes/manifests/kube-controller-manager.manifest.
In the proposed architecture, 3 instances of controller manager run in the same clustered mode as schedulers, with 1 active leader and 2 stand-by spares.
The same set of parameters controls election of leader for controller manager as well:
- Leader election parameter for controller manager must be “true”
- Leader elect lease duration
- Leader elect renew deadline
- Leader elect retry period
kube-proxy¶
Kubernetes proxy forwards traffic to alive Kubernetes Pods. This is an internal component that exposes Services created via Kubernetes API inside the cluster. Some Ingress/Proxy server is required to expose services to outside of the cluster via globally routed virtual IP (see above).
The pod kube-proxy runs on every node in the cluster. It is a static
pod defined by manifest file
/etc/kubernetes/manifests/kube-proxy.manifest. It includes single
container that runs hyperkube application in proxy mode.
kubedns¶
Kubernetes DNS schedules a DNS Pod and Service on the cluster, and configures the kubelets to tell individual containers to use the DNS Service’s IP to resolve DNS names.
The DNS pod (kubedns) includes 3 containers:
kubednsis a resolver that communicates to API server and controls DNS names resolvingdnsmasqis a relay and cache providerhealthzis a health check service
In the proposed architecture, kubedns pod is controller by
ReplicationController with replica factor 1, which means that only
one instance of the pod is working in a cluster at any time.
Etcd Cluster¶
Etcd is a distributed, consistent key-value store for shared configuration and service discovery, with a focus on being:
- Simple: well-defined, user-facing API (gRPC)
- Secure: automatic TLS with optional client cert authentication
- Fast: benchmarked 10,000 writes/sec
- Reliable: properly distributed using Raft
etcd is written in Go and uses the Raft consensus algorithm to
manage a highly-available replicated log.
Every instance of etcd can operate in one of the two modes:
- full mode
- proxy mode
In full mode, the instance participates in Raft consensus and has persistent storage.
In proxy mode, etcd acts as a reverse proxy and forwards client
requests to an active etcd cluster. The etcd proxy does not
participate in the consensus replication of the etcd cluster,
thus it neither increases the resilience nor decreases the write
performance of the etcd cluster.
In proposed architecture, etcd runs as a static container
under control of host operating system. See details below in
Installation section. The assumed version of etcd in this
proposal is etcdv2.
Etcd full daemon¶
There are three instances of etcd running in full mode on Master
nodes in the proposed solution. This ensures the quorum in the cluster
and resiliency of service.
Etcd native proxy¶
Etcd in proxy mode runs on every node in Kubernetes cluster, including Masters and Minions. It automatically forwards requests to active Etcd cluster members. According to the documentation it’s recommended etcd cluster architecture.
Calico¶
Calico is an L3 overlay network provider for Kubernetes. It propagates internal addresses of containers via BGP to all minions and ensures connectivity between containers.
Calico uses etcd as a vessel for its configuraiton information. Separate etcd cluster is recommended for Calico instead of sharing one with Kubernetes.
calico-node¶
In the proposed architecture, Calico is integrated with Kubernetes as Common Network Interface (CNI) plugin.
The Calico container called calico-node runs on every node in
Kubernetes cluster, including Masters and Minions. It is controlled
by operating system directly as systemd service.
The calico-node container incorporates 3 main services of Calico:
- Felix,
- the primary Calico agent. It is responsible for programming routes and ACLs, and anything else required on the host, in order to provide the desired connectivity for the endpoints on that host.
- BIRD
- is a BGP client that distributes routing information.
- confd is a dynamic configuration manager for BIRD, triggered
- automatically by updates in the configuration data.
High Availability Architecture¶
Proxy server¶
Proxy server should forward traffic to alive backends, health checking mechanism has to be in place to stop forwarding traffic to unhealthy backends.
Nginx is used to implement Proxy service. It is deployed in a static pod, one pod per cluster. It provides access to K8s API endpoint on a single by redirecting requests to instances of kube-apiserver in a round-robin fashion. It exposes the endpoint both to external clients and internal clients (i.e. Kubernetes minions).
SSL termination¶
SSL termination can be optionally configured on Nginx server. From there, traffic to instances of kube-apiserver will go over internal K8s network.
Proxy Resiliency Alternatives¶
Since the Proxy Server is a single point of failure for Kubernetes API and exposed Services, it must run in highly available configuration. The following alternatives were considered for high availability solution:
- Keepalived Although Keepalived has problems with split brain detection there is a subproject in Kubernetes which uses Keepalived with an attempt to implement VIP management.
- OSPF Using OSPF routing protocol for resilient access and failover between Proxy Servers requires configuration of external routers consistently with internal OSPF configurations.
- VIP managed by cluster management tools Etcd might serve as a cluster mangement tool for a Virtual IP address where Proxy Server is listening. It will allow to converge the technology stack of the whole solution.
- DNS-based reservation Implementing DNS based High Availability is very problematic due to caching on client side. It also requires additional tools for fencing and failover of faulty Proxy Servers.
Resilient Kubernetes Configuration¶
In the proposed architecture, there is a single static pod with Proxy Server running under control of Kubelet on every Minion node.
Each of the 3 Master nodes runs its own instance of kube-apiserver
on localhost address. All services working on a Master node address
the Kubernetes API locally. All services on Minion nodes connect to
the API via local instance of Proxy Server.
Etcd daemons forming the cluster run on Master nodes. Every node in the cluster also runs etcd-proxy. This includes both Masters and Minions. Any service that requires access to etcd cluster talks to local instance of etcd-proxy to reach it. External access to etcd cluster is restricted.
Calico node container runs on every node in the cluster, including Masters and Minions.
The following diagram summarizes the proposed architecture.
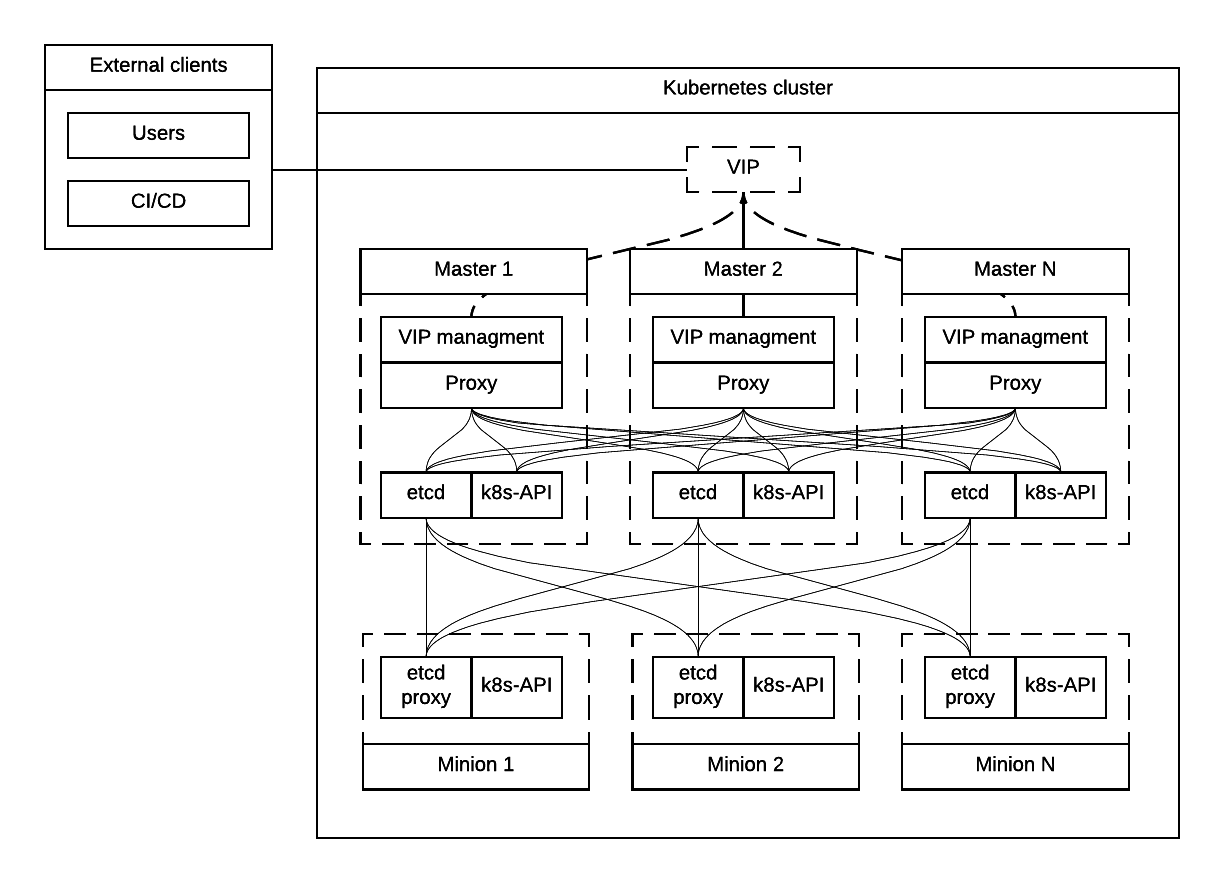
Alternative approaches to the resiliency of Kubernetes cluster were considered, researched and summarized in Appendix A. High Availability Alternatives.
Next steps in development of this architecture include implementation of a Proxy server as an Ingress Controller. It will allow for closer integration with K8s in terms of pods mobility and life-cycle management operations. For example, Ingress Controller can be written to only relay incoming requests to updated nodes during rolling update. It also allows to manage virtual endpoint using native Kubernetes tools (see below).
Logging¶
Logs collection was made by Heka broker running at all nodes in the Kubernetes cluster. It used Docker logging in configuration when all logs are written to a volume. Heka reads files from the volume using Docker plugin and uploads them to ElasticSearch storage.
Installation¶
This section describes the installation of Kubernetes cluster on pre-provisioned nodes.
The following list shows containers that belong to Kubernetes Master Tier and run under control of systemd on Master and/or Minion nodes, along with a short explaination why it is necessary in every case:
- Etcd
- Should have directory mounted from host system.
- Calico
- Depending on network architecture it may be required to disable node-to-node mesh and configure route reflectors instead. This is especially recommended for large scale deployments (see below).
- Kubelet
- Certificates directory should be mounted from host system in Read Only mode.
The following containers are defined as ReplicationController objects in Kubernetes API:
- kubedns
All other containers are started as static pods by Kubelet in ‘kube-system’ namespace of Kubernetes cluster. This includes:
- kube-apiserver
- kube-scheduler
- kube-controller-manager
- Proxy Server (nginx)
- dnsmasq
Note
An option to start all other services in Kubelet is being considered. There is a potential chicken-and-egg type issue that Kubelet requires CNI plugin to be configured prior its start, as a result when Calico pod started by Kubelet, it tries to perform a hook for a plugin and fails. Thi happens if a pod uses host networking as well. After several attempts it starts the container, but currently such cases are not handled explicitly.
Common practices¶
- Manifests for static Pods should be mounted (read only) from host system, it will simplify update and reconfiguration procedure.
- SSL certificates and any secrets should be mounted (read only) from host system, also they should have appropriate permissions.
Installation workflow¶
- Ansible retrieves SSL certificates.
- Ansible installs and configures docker.
- Systemd config
- Use external registry
- All control-plane related Pods must be started in separate namespace
kube-system. This will allow to restrict access to control plane pods in future. - Ansible generates manifests for static pods and writes them to
/etc/kubernetes/manifestsdirectory. - Ansible generates configuration files, systemd units and services for Etcd, Calico and Kubelet.
- Ansible starts all systemd-based services listed above.
- When Kubelet is started, it reads manifests and starts services defined as static pods (see above).
- Run health-check.
- This operations are repeated for every node in the cluster.
Scaling to 1000 Nodes¶
Scaling Kubernetes cluster to magnitude of 1000 nodes requires certain changes to confiugration and, in a few cases, the source code of components.
The following modifications were made to default configuration deployed by Kargo installer.
Proxy Server¶
Default configuration of parameter proxy_timteout in Nginx
caused issues with long-polling “watch” requests from kube-proxy
and kubelet to apiserver. Nginx by default terminates such sessions
in 3 seconds. Once session is cut, Kubernetes client has to restore
it, including repeat of SSL handshake, and at scale it generates
high load on Kube API servers, about 2000% of CPU in given
configuration.
This problem was solved by changing the default value (3s) to more appropriate value of 10m:
proxy_timeout: 10m
As a result, CPU usage of kube-apiserver processes dropped
10 times, to 100-200%.
The corresponding change was proposed into upstream Kargo.
kube-apiserver¶
The default rate limit of Kube API server proved to be too low for
the scale of 1000 nodes. Long before the top load on the API server,
it starts to return 429 Rate Limit Exceeded HTTP code.
Rate limits were adjusted by passing new value to kube-apiserver
with --max-requests-inflight command line option. While default
value for this parameter is 400, it has to be adjusted to 2000 at
the given scale to accommodate to actual rate of incoming requests.
kube-scheduler¶
Scheduling of so many pods with anti-affinity rules, as required by
CCP architecture, puts kube-scheduler under high load. A few
optimizations were made to its code to accommodate to the 1000
node scale.
- scheduling algorithm improved to reduce a number of expensive operations: pull request.
- cache eviction/miss bug in scheduler has to be fixed to improve handling of anti-affinity rules. It was worked around in Kubernetes, but root cause still requires effort to fix.
The active scheduler was placed to dedicated hardware node in order to cope with high load while scheduling large number of OpenStack control plane pods.
kubedns and dnsmaq¶
Default settings of resource limits for dnsmasq in Kargo don’t fit for scale of 1000 nodes. The following settings must be adjusted to accommodate for that scale:
dns_replicas: 6dns_cpu_limit: 100mdns_memory_limit: 512Midns_cpu_requests 70mdns_memory_requests: 70Mi
A number of instances of kubedns pod was increased to 6 to
handle load generated by the cluster of the given size.
Following limits were tuned in dnsmasq configuration:
number of parallel connections the daemon could handle was increased to 1000:
--dns-forward-max=1000
size of cache was set to the highest possible value of 10000
Ansible¶
Several parameters in Ansible configuration have to be adjusted to improve its robustness in higher scale environments. This includes the following:
forksfor a number of parallel processes to spawn when communicating to remote hosts.timeoutdefault SSH timeout on connection attepmts.download_run_onceanddownload_localhostboolean parameters control how container images are being distributed to nodes.
Calico¶
In the tested architecture Calico was configured without route reflectors for BIRD BGP daemons. Therefore, Calico established a full mesh connections between all nodes in the cluster. This operation took significant time during node startup.
It is recommended to configure route reflectors for BGP daemons in all cases at scale of 1000 nodes. This will reduce the number of BGP connections across the cluster and improve startup time for nodes.
Lifecycle Management¶
Validation¶
Many LCM use-cases may cause destructive consequences for the cluster, we should cover such use-cases with static validation, because it’s easy to make a mistake when user edits the configuration files.
Examples of such use-cases:
- Check that there are nodes with Master related services.
- Check that quorum for etcd cluster is satisfied.
- Check that scale down or node decommissioning does not cause data lose.
The validation checks should be implemented on CI/CD level, when new patch is published, a set of gates should be started, where validation logic is implemented, based on gates configuration they may or may not block the patch for promotion to staging or production.
Scale up¶
User assigns a role to a new node in configuration file, after changes are committed in the branch, CI/CD runs Ansible playbooks.
Scale down¶
Scaledown can also be described as Node Deletion. During scaledown user should remove the node from configuration file, and add the node for decommissioning.
Master¶
- Run Ansible against the cluster to make sure that the node being deleted is not present in any service’s configuration.
- Run node decommissioning.
Minion¶
- Disable scheduling to the minion being deleted.
- Move workloads away from the minion.
- Run decommission of services managed by Ansible (see section Installation).
- Run node decommissioning.
Test Plan¶
Initial deploy
Tests must verify that Kubernetes cluster has all required services and generally functional in terms of standard operations, e.g. add, remove a pod, service and other entities.
Scaleup
Verify that Master node and Minion node could be added to the cluster. The cluster must remain functional in terms defined above after the scaleup operation.
Scaledown
Verify that the cluster retains its functionality after removing Master or Minion node. This test set is subject to additional limitations to number of removed nodes since there is a absolute minimum or nodes required for Kubernetes cluster to function.
Update
Verify that updating single service or a set of thereof doesn’t degrade functions of the cluster compared to its initial deploy state.
- Intrusive
- Non-intrusive
Rollback
Verify that restoring version of one or more components to previously working state after they were updated does not lead to degradation of functions of the cluster.
Rollout abort
Verify that if a Rollback operation is aborted, the cluster can be reverted to working state by resuming the operation.
Updating¶
Updating is one the most complex Lifecycle management use-cases, that is the reason it was decided to allocate dedicated section for that. We split updates use-cases into two groups. The first group “Non-intrusive”, is the simplest one, update of services which do not cause workload downtime. The second “Intrusive”, is more complicated since may cause updates downtime and has to involve a sequence of actions in order to move stateful workload to different node in the cluster.
Update procedure starts with publishing of new version of image in Docker repository. Then a service’s metadata should be updated to new version by operator of the cloud in staging or production branch of configuration repository for Kubernetes cluster.
Non-intrusive¶
Non-intrusive type of update does not cause workload downtime, hence it does not require workload migration.
Master¶
Update of Master nodes with minimal downtime can be achieved if Kubernetes installed in HA mode, minimum 3 nodes.
Key points in updating Master related services:
- First action which has to be run prior to update is backup of Kubernetes related stateful services (in our case it is etcd).
- Update of services managed by Ansible is done by ensuring version of running docker image and updating it in systemd and related services.
- Update of services managed by Kubelet is done by ensuring of files with Pod description which contain specific version.
- Nodes has to be updated one-by-one, without restarting services on all nodes simultaneously.
Minion¶
Key points in updating Minion nodes, where workload is run:
- Prior to restarting Kubelet, Kubernetes has to be notified that Kubelet is under maintenance and its workload must not be rescheduled to different node.
- Update of Kubelet should be managed by Ansible.
- Update of services managed by Kubelet is done by ensuring of files with Pod description.
Intrusive¶
Intrusive update is an update which may cause workload downtime, separate update flow for such kind of updates has to be considered. In order to provide update with minimal downtime for the tenant we want to leverage VMs Live Migration capabilities. Migration requires to start maintenance procedure in the right order by butches of specific sizes.
Common¶
- Services managed by Ansible, are updated using Ansible playbooks which triggers pull of new version, and restart.
- If service is managed by Kubelet, Ansible only updates static manifest and Kubelet automatically updates services it manages
Master¶
Since master node does not have user workload update the key points for update are the same as for “Non-intrusive” use-cases.
Minion¶
User’s workload is run on Minion nodes, in order to apply intrusive updates, rollout system has to move workload to a different node. On big clusters updates in butch-update will be required, to achieve faster rollout.
Key requirements for Kubernetes installer and orchestrator:
- Kubernetes installer is agnostic of which workloads run in Kubernetes cluster and in VMs on top of OpenStack which works as Kubernetes application.
- Kubernetes installer should receive rollout plan, where the order, and grouping of nodes, update pf which can be rolled out in parallel are defined. This update plan will be generated by different tool, which knows “something” about types of workload run on the cluster.
- In order to move workload to different node, installer has to trigger
workload evacuation from the node.
- Scheduling of new workload to the node should be disabled.
- Node has to be considered as in maintenance mode, that unavailability of kubelet does not cause workload rescheduling.
- Installer has to trigger workload evacuation in kubelet, kubelet should use hooks defined in Pods, to start workload migration.
- In rollout plan it should be possible to specify, when to fail
rollout procedure.
- If some percent of nodes failed to update.
- There may be some critical for failure nodes, it’s important to provide per node configuration, if it is important to stop rollout procedure if this node failed to be updated.
Limitations¶
Hyperkube¶
Current Kubernetes deliver mechanism relies on Hyperkube distribution. Hyperkube is a single binary file which contains all set of core Kubernetes components, e.g. API, Scheduler, Controller, etc. The problem with this approach is that bug-fix for API causes update of all core Kubernetes containers, even if API is installed on few controllers, new version has to be rolled out to all thousands of minions.
Possible solutions:
- For different roles rollout different versions of Hyperkube. This approach significantly complicates versions and fixes tracking process.
- Make split between those roles and create for them different images. The problem will remain since most of the core components are developed in a single repository and released together, hence it is still an issue, if release tag is published on the repo, rebuild of all core components will be required.
For now we go with native way of distribution until better solution is found.
Update Configuration¶
Update of configurations in most of the cases should not cause downtime.
- Update of Kubernetes and related services (calico, etcd, etc).
- Rotation of SSL certificates (e.g. those which are used for Kubelet authentication)
Abort Rollout¶
Despite the fact that this operation may be dangerous, user should be able to interrupt update procedure.
Troubleshooting¶
There should be a simple way to provide for a developer tooling for debugging and troubleshooting. These tools should not be installed on each machine by default, but there should be a simple way to get this tools installed on demand.
- Image with all tools required for debugging
- Container should be run in privileged mode with host networking.
- User can rollout this container to required nodes using Ansible.
Example of tools which may be required:
- Sysdig
- Tcpdump
- Strace/Ltrace
- Clients for etcd, calico etc
- ...
Open questions¶
- Networking node?
Contributors¶
- Evgeny Li
- Matthew Mosesohn
- Bogdan Dobrelya
- Jedrzej Nowak
- Vladimir Eremin
- Dmytriy Novakovskiy
- Michael Korolev
- Alexey Shtokolov
- Mike Scherbakov
- Vladimir Kuklin
- Sergii Golovatiuk
- Aleksander Didenko
- Ihor Dvoretskyi
- Oleg Gelbukh
Appendix A. High Availability Alternatives¶
This section contains some High Availability options that were considered and researched, but deemed too complicated or too risky to implement in the first iteration of the project.
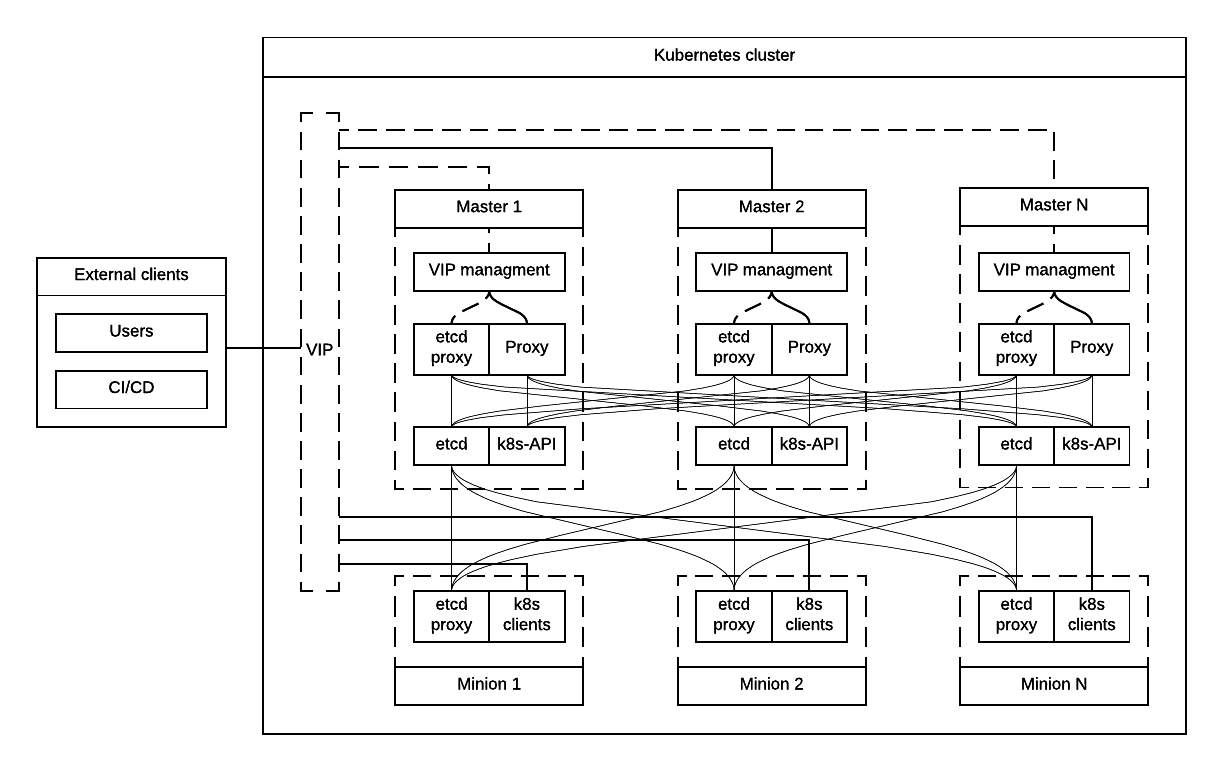
Option #1 VIP for external and internal with native etcd proxy¶
First approach to Highly Available Kubernetes with Kargo assumes using VIP for external and internal access to Kubernetes API, etcd proxy for internal access to etcd cluster.
- VIP for external and internal access to Kubernetes API.
- VIP for external access to etcd.
- Native etcd proxy on each node for internal access to etcd cluster.
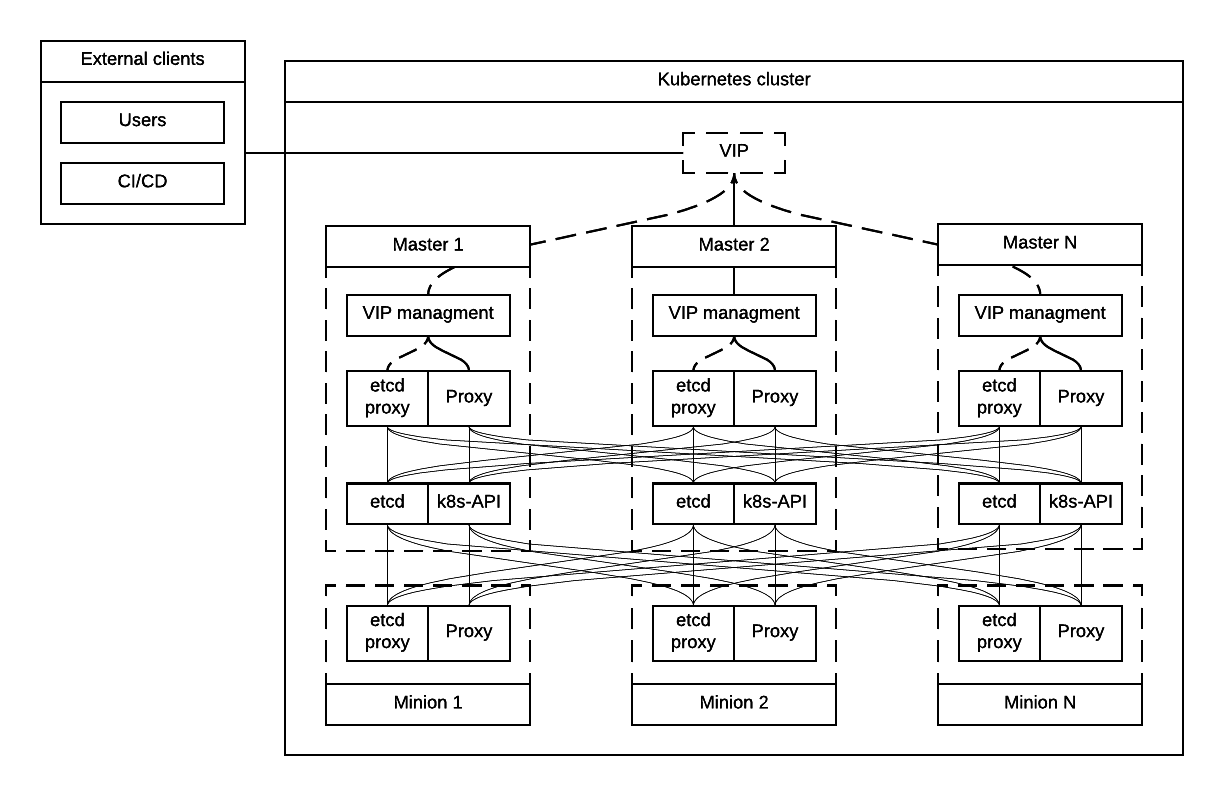
Option #2 VIP for external and Proxy on each node for internal¶
The second considered option is each node that needs to access Kubernetes API also has Proxy Server installed. Each Proxy forwards traffic to alive Kubernetes API backends. External clients access Etcd and Kubernetes API using VIP.
- Internal access to APIs is done via proxies which are installed locally.
- External access is done via Virtual IP address.
Option #3 VIP for external Kubernetes API on each node¶
Another similar to “VIP for external and Proxy on each node for internal” option, may be to install Kubernetes API on each node which requires access to it instead of installing Proxy which forwards the traffic to Kubernetes API on master nodes.
- VIP on top of proxies for external access.
- Etcd proxy on each node for internal services.
- Kubernetes API on each node, where access to Kubernetes is required.
This option was selected despite potential limitations listed above.
Option #4 VIP for external and internal¶
In order to achieve High Availability of Kubernetes master proxy server on every master node can be used, each proxy is configured to forward traffic to all available backends in the cluster (e.g. etcd, kubernetes-api), also there has to be a mechanism to achieve High Availability between these proxies, it can be achieved by VIP managed by cluster management system (see “High Availability between proxies” section).
- Internal and External access to Etcd or Kubernetes cluster is done via Virtual IP address.
- Kubernetes API also access to Etcd using VIP.

Option #5 VIP for external native Kubernetes proxy for internal¶
We considered using native Kubernetes proxy for forwarding traffic between APIs. Kubernetes proxy cannot work without Kubernetes API, hence it should be installed on each node, where Kubernetes proxy is installed. If Kubernetes API is installed on each node, there is no reason to use Kubernetes proxy to forward traffic with it, internal client can access the Kubernetes API through localhost.